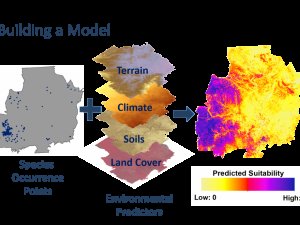
Ok, quindi questo è meno per illustrare un concetto di base, ma è molto interessante sia visivamente che in termini di applicazioni. Penso che mostrare alle persone ciò che alla fine possono ottenere con ciò che stanno imparando sia una grande forma di motivazione, quindi puoi presentarlo come un esempio di sviluppo e applicazione di modelli statistici, che dipende da tutti i concetti statistici più fondamentali che stanno imparando. Con questo, vi presento ...
Species Distribution Modelling
In realtà è un argomento molto ampio con molte sfumature in termini di tipi di dati, raccolta di dati, configurazione del modello, ipotesi, applicazioni, interpretazioni, ecc. Ma in parole semplici, prendi informazioni campione su dove si trova una specie, quindi utilizzare quelle posizioni per campionare variabili ambientali potenzialmente rilevanti (ad esempio, dati climatici, dati sul suolo, dati sull'habitat, elevazione, inquinamento luminoso, inquinamento acustico, ecc.), sviluppare un modello utilizzando i dati (ad esempio, GLM, modello di processo puntuale, ecc.) , quindi utilizza quel modello per prevedere attraverso un paesaggio utilizzando le tue variabili ambientali. A seconda di come è stato impostato il modello, ciò che è previsto potrebbe essere un potenziale habitat adatto, probabili aree di occorrenza, distribuzione delle specie, ecc. È inoltre possibile modificare le variabili ambientali per vedere come influiscono su questi risultati. Le persone hanno utilizzato gli SDM per trovare popolazioni di una specie precedentemente sconosciute, li hanno usati per scoprire nuove specie, con dati storici sul clima li hanno usati per prevedere a ritroso nel tempo dove si trovava una specie e come è arrivata dove si trovava. è oggi (anche attraverso i periodi di glaciazione) e con cose come previsioni climatiche future e perdita di habitat, vengono utilizzate per prevedere come le attività umane influenzeranno la specie in futuro. Questi sono solo alcuni esempi e se avrò tempo più tardi troverò e collegherò documenti interessanti. Nel frattempo ecco una rapida immagine che ho trovato che illustra le basi: