Poiché calcolo valori leggermente diversi della divergenza KL rispetto a quanto riportato qui, iniziamo con il mio tentativo di riprodurre i grafici di questi PDF:
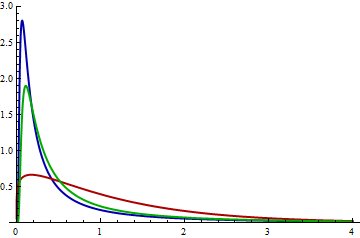
La distanza KL da $ F $ a $ G $ è l'aspettativa, secondo la legge della probabilità $ F $ , della differenza nei logaritmi dei loro PDF. Esaminiamo quindi da vicino i log PDF. I valori vicini a 0 contano molto, quindi esaminiamoli. La figura successiva mostra i file PDF di log nella regione da $ x = 0 $ a $ x = 0.10 $ :
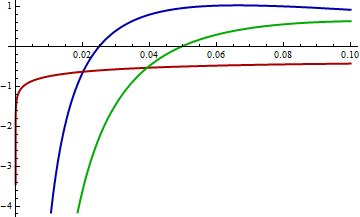
Mathematica calcola che KL (rosso, blu) = 0,574461 e KL (rosso, verde) = 0,641924. Nel grafico è chiaro che tra 0 e 0,02, approssimativamente, log (verde) differisce molto di più da log (rosso) rispetto a log (blu). Inoltre, in questo intervallo c'è ancora una densità di probabilità sostanzialmente grande per il rosso: il suo logaritmo è maggiore di -1 (quindi la densità è maggiore di circa 1/2).
Dai un'occhiata alle differenze nei logaritmi . Ora la curva blu è la differenza log (rosso) - log (blu) e la curva verde è log (rosso) - log (verde). Le divergenze KL (rispetto al rosso) sono le aspettative (secondo il pdf rosso) di queste funzioni.
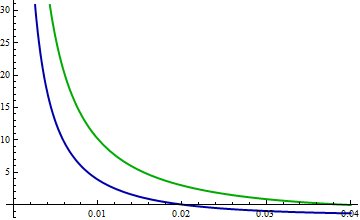
(Notare il cambiamento nella scala orizzontale, che ora si concentra maggiormente vicino a 0.)
Molto approssimativamente, sembra che una tipica distanza verticale tra queste curve sia di circa 10 nell'intervallo da 0 a 0,02, mentre un valore tipico per il pdf rosso è di circa 1/2. Pertanto, questo intervallo da solo dovrebbe aggiungere circa 10 * 0,02 / 2 = 0,1 alle divergenze KL. Questo spiega quasi la differenza di 0,067. Sì, è vero che i logaritmi blu sono più lontani dei logaritmi verdi per valori orizzontali maggiori, ma le differenze non sono così estreme e il PDF rosso decade rapidamente.
In breve, differenze estreme nelle code a sinistra delle distribuzioni blu e verde, per valori compresi tra 0 e 0,02, spiegano perché KL (rosso, verde) supera KL (rosso, blu).
Per inciso , KL (blu, rosso) = 0,454776 e KL (verde, rosso) = 0,254469.
Codice
Specifica le distribuzioni
red = GammaDistribution [1 / .85, 1]; green = InverseGaussianDistribution [1, 1/3.]; blue = InverseGaussianDistribution [1, 1/5.];
Calcola KL
Clear [kl]; (* Integrazione numerica tra endpoint specificati. *) kl [pF_, qF_, l_, u_]: = Modulo [{p, q}, p [x_]: = PDF [pF, x]; q [x_]: = PDF [qF, x]; NIntegrate [p [x] (Log [p [x]] - Log [q [x]]), {x, l, u}, Method -> "LocalAdaptive"]]; (* Integrazione sull'intero dominio. * ) kl [pF_, qF_]: = Modulo [{p, q}, p [x_]: = PDF [pF, x]; q [x_]: = PDF [qF, x]; Integra [p [x] (Log [p [x]] - Log [q [x]]), {x, 0, \ [Infinity]}]]; kl [rosso, blu] kl [rosso, verde] kl [blue, red, 0, \ [Infinity]] kl [green, red, 0, \ [Infinity]]
Crea le trame
Cancella [plot]; plot [{f_, u_, r_}]: = Plot [Valuta [f [#, x] & / @ {blue, red, green}], {x, 0, u}, PlotStyle -> {{Thick, Darker [Blue]}, {Thick, Darker [Red]}, {Thick, Darker [Green]}}, PlotRange -> r, Exclusions -> {0}, ImageSize -> 400]; Tabella [plot [f], {f, {{PDF, 4, {Full, {0, 3}}}, {Log [PDF [##]] &, 0.1, {Full, Automatic}}} }] // TableFormPlot [{Log [PDF [red, x]] - Log [PDF [blue, x]], Log [PDF [red, x]] - Log [PDF [green, x]]}, {x , 0, 0.04}, PlotRange -> {Full, Automatic}, PlotStyle -> {{Thick, Darker [Blue]}, {Thick, Darker [Green]}}]