È insolito non inserire un'intercetta e generalmente sconsigliabile: dovresti farlo solo se sai che è 0, ma penso che (e il fatto che non puoi confrontare $ R ^ 2 $ per accoppiamenti con e senza intercetta) è già ben e veramente coperto (se forse un po 'sopravvalutato nel caso dell'intercetta 0); Voglio concentrarmi sul tuo problema principale, che è che hai bisogno che la funzione adattata sia positiva, anche se torno al problema dell'intercetta 0 in parte della mia risposta.
Il modo migliore per ottenere sempre adattamento positivo è adattarsi a qualcosa che sarà sempre positivo; in parte ciò dipende dalle funzioni che devi adattare.
Se il tuo modello lineare era in gran parte conveniente (piuttosto che derivare da una relazione funzionale nota che potrebbe derivare da un modello fisico, diciamo), allora tu potrebbe invece funzionare con il tempo di log; il modello adattato è quindi garantito come positivo in $ t $. In alternativa, potresti lavorare con la velocità piuttosto che con il tempo, ma poi con gli adattamenti lineari potresti avere un problema con velocità piccole (tempi lunghi).
Se sai che la tua risposta è lineare nei predittori, puoi tentare di adattare una regressione vincolata, ma con la regressione multipla la forma esatta di cui hai bisogno dipenderà dalle tue x particolari (non esiste un vincolo lineare che funzionerà per tutti i $ x $), quindi è un bit ad-hoc.
Puoi anche guardare i GLM che possono essere usati per adattare i modelli che hanno valori adattati non negativi e possono (se necessario) anche avere $ E (Y) = X \ beta $ .
Ad esempio, si può adattare una gamma GLM con collegamento identità. Non dovresti finire con un valore adattato negativo per nessuna delle tue x (ma potresti forse avere problemi di convergenza in alcuni casi se forzi il collegamento di identità dove realmente non si adatta).
Ecco un esempio: il set di dati cars in R, che registra la velocità e le distanze di arresto (la risposta).
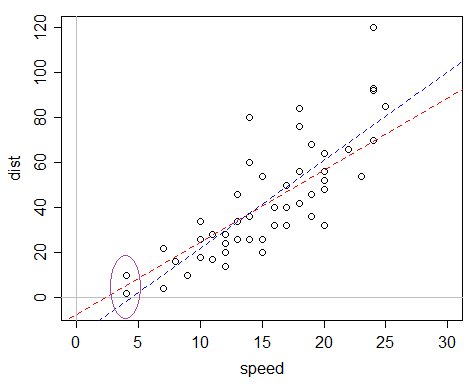
Si potrebbe dire "oh, ma la distanza per la velocità 0 è garantita essere 0, quindi dovremmo omettere l'intercetta" ma il problema con questo ragionamento è che il modello è specificato male in diversi modi e quell'argomento funziona solo bene abbastanza quando il modello non è specificato male - un modello lineare con 0 intercetta non si adatta affatto bene in questo caso, mentre uno con un'intercetta è in realtà un'approssimazione decente anche se in realtà non è "corretto".
Il problema è che, se si adatta una normale regressione lineare, l'intercetta adattata è piuttosto negativa, il che fa sì che i valori stimati siano negativi.
La linea blu è la vestibilità OLS; il valore adattato per i valori x più piccoli nel set di dati è negativo. La linea rossa è la gamma GLM con collegamento di identità: pur avendo un'intercetta negativa, ha solo valori adattati positivi. Questo modello ha una varianza proporzionale alla media, quindi se trovi che i tuoi dati sono più distribuiti con l'aumentare del tempo previsto, potrebbe essere particolarmente adatto.
Quindi questo è un possibile approccio alternativo che potrebbe valere la pena provare. È quasi facile come inserire una regressione in R.
Se non hai bisogno del collegamento di identità, potresti considerare altre funzioni di collegamento, come il collegamento di registro e il collegamento inverso, che si riferiscono alle trasformazioni già discusso, ma senza la necessità di una trasformazione effettiva.
Poiché le persone di solito lo chiedono, ecco il codice per il mio grafico:
plot (dist ~ speed, data = cars, xlim = c (0, 30), ylim = c (-5,120)) abline (h = 0, v = 0, col = 8) abline (glm (dist ~ speed, data = cars, family = Gamma (link = identity)), col = 2 , lty = 2) abline (lm (dist ~ speed, data = cars), col = 4, lty = 2)
(L'ellisse è stata aggiunta a mano in seguito, sebbene sia abbastanza facile da fare anche in R)