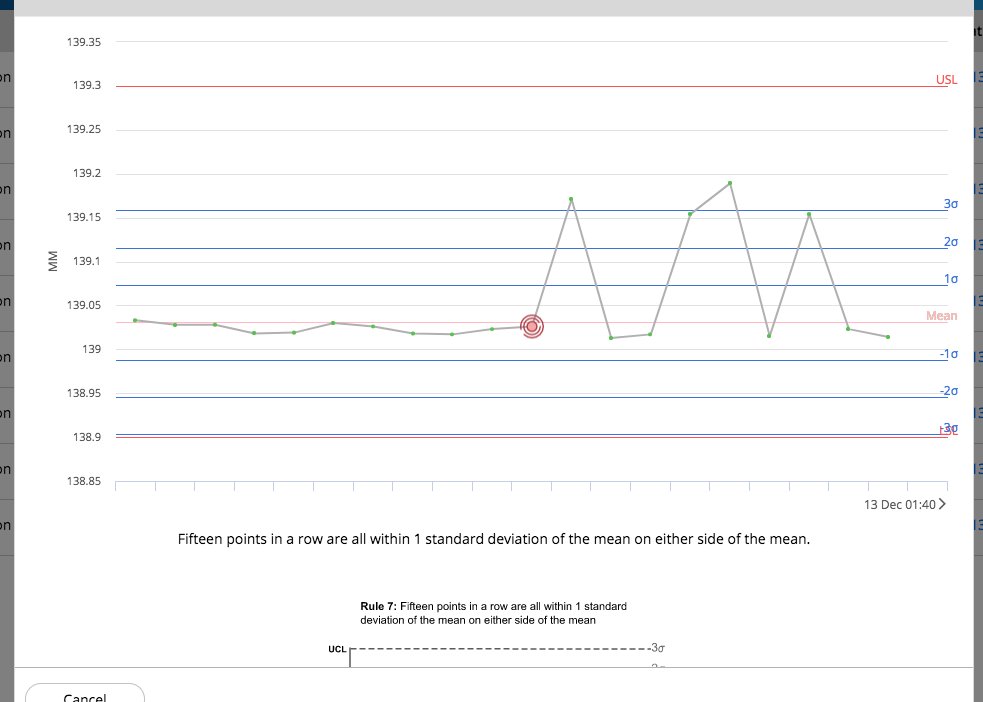
disclaimer: questo metodo è ad hoc e senza uno studio rigoroso. Utilizzare a proprio rischio :)
Quello che ho trovato abbastanza buono è stato ridurre la rilevanza di un contributo in punti alla media da parte di square del suo numero di deviazioni standard dalla media , ma solo se il punto è più di una deviazione standard dalla media.
Passaggi:
- Calcola la media e la deviazione standard come al solito.
- Ricalcola la media, ma questa volta, per ogni valore, se è più di una deviazione standard dalla media, riduci il suo contributo alla media. Per ridurre il suo contributo, dividere il suo valore per il quadrato del suo numero di deviazioni prima di aggiungere al totale. Anche perché contribuisce di meno, dobbiamo ridurre N, quindi sottrarre 1-1 / (quadrato della deviazione dei valori) da N.
- Ricalcola la deviazione standard, ma utilizza questa nuova media anziché la vecchia media.
esempio:
stddev = 0,5
media = 10
valore = 11
quindi, deviazioni = distanza dalla media / stddev = | 10-11 | /0.5 = 2
quindi il valore cambia da 11 a 11 / (2) ^ 2 = 11/4
anche N cambia, è ridotto a N-3/4.
codice:
def mean (data):
"" "Restituisce la media aritmetica dei dati campione." ""
n = len (dati)
se n < 1:
raise ValueError ('la media richiede almeno un punto dati')
return 1.0 * sum (data) / n # in Python 2 usa sum (data) / float (n)
def _ss (dati):
"" "Restituisce la somma delle deviazioni quadrate dei dati di sequenza." ""
c = media (dati)
ss = sum ((x-c) ** 2 per x nei dati)
return ss, c
def stddev (dati, ddof = 0):
"" "Calcola la deviazione standard della popolazione
per impostazione predefinita; specificare ddof = 1 per calcolare il campione
deviazione standard."""
n = len (dati)
se n < 2:
raise ValueError ('la varianza richiede almeno due punti dati')
ss, c = _ss (dati)
pvar = ss / (n-ddof)
return pvar ** 0,5, c
def rob_adjusted_mean (valori, s, m):
n = 0,0
tot = 0,0
per v nei valori:
diff = abs (v - m)
deviazioni = diff / s
se deviazioni > 1:
# è un valore anomalo, quindi riduci la sua rilevanza / ponderazione per il quadrato del suo numero di deviazioni
n + = 1.0 / deviazioni ** 2
tot + = v / deviazioni ** 2
altro:
n + = 1
tot + = v
ritorno tot / n
def rob_adjusted_ss (valori, s, m):
"" "Restituisce la somma delle deviazioni quadrate dei dati di sequenza." ""
c = rob_adjusted_mean (valori, s, m)
ss = sum ((x-c) ** 2 for x in values)
return ss, c
def rob_adjusted_stddev (data, s, m, ddof = 0):
"" "Calcola la deviazione standard della popolazione
per impostazione predefinita; specificare ddof = 1 per calcolare il campione
deviazione standard."""
n = len (dati)
se n < 2:
raise ValueError ('la varianza richiede almeno due punti dati')
ss, c = rob_adjusted_ss (data, s, m)
pvar = ss / (n-ddof)
return pvar ** 0,5, c
s, m = stddev (valori, ddof = 1)
stampa s, m
s, m = rob_adjusted_stddev (valori, s, m, ddof = 1)
stampa s, m
output prima e dopo la regolazione delle mie 50 misurazioni:
0.0409789841609 139.04222
0,0425867309757 139,030745443