Sebbene Henry abbia già fornito un modo per calcolare il numero esattamente contando tutte le partizioni, potrebbe essere interessante conoscere due metodi approssimativi.
Inoltre, esiste un calcolo esatto alternativo basato su variabili distribuite di Poisson condizionali.
Simulazione computazionale
Non sarai facilmente in grado di calcolare tutte le $ 12 ^ {18} $ possibilità (e non sarà facile aumentare il problema), ma puoi fare in modo che un computer simuli in modo casuale un sottoinsieme dei possibili modi e ottenere una distribuzione da quelle simulazioni.
# funzione per campionare 18 mesi di nascita
# e ottieni il numero massimo di mesi simili
monthsample <- function () {
x <- sample (1: 12,18, replace = TRUE) # sample
n <- max (table (x)) # ottiene il massimo
ritorno (n)
}
# campiona un milione di volte
y <- replicate (10 ^ 6, monthsample ())
# ottiene la frequenza utilizzando un istogramma
h<-hist (y, interruzioni = seq (-0.5,18.5,1))
Approssimazione con Poissonation
La frequenza del numero di compleanni in un determinato mese è approssimativamente distribuita Poisson / binomiale. In base a ciò possiamo calcolare la probabilità che il numero di compleanni in un determinato mese non superi un certo valore e, prendendo la potenza di dodici, calcoliamo la probabilità che ciò accada per tutti i dodici mesi.
Nota: qui trascuriamo il fatto che il numero di compleanni è correlato, quindi questo ovviamente non è esatto.
# approssimazione con distribuzione di Poisson
t <- 0:18
z <- ppois (t, 1.5) ^ 12 # P (max < = t)
dz <- diff (z) # P (max = t + 1)
Calcolo con la rappresentazione di Bruce Levin
Nei commenti Whuber ha indicato il pacchetto pmultinom. Questo pacchetto è basato su Bruce Levin 1981 "A Representation for Multinomial Cumulative Distribution Functions" in Ann. Statista. Volume 9 . Il risultato dei mesi di nascita (che è più precisamente distribuito secondo una distribuzione multinomiale) è rappresentato come variabili distribuite di Poisson indipendenti. Ma a differenza del calcolo ingenuo prima menzionato, la distribuzione di quelle variabili distribuite di Poisson è considerata condizionale sul fatto che la somma totale sia uguale a $ n = 18 $ .
Quindi sopra abbiamo calcolato $$ P (X_1, X_2, \ ldots, X_ {12} \ leq 4) = P (X_1 \ leq 4) \ cdot P (X_1 \ leq 4) \ cdot \ ldots \ cdot P (X_ {12} \ leq 4) $$ ma avremmo dovuto calcolare la probabilità condizionale che le variabili distribuite di Poisson fossero tutte uguali o inferiori di $$ P (X_1, X_2, \ ldots, X_ {12} \ leq 4 \ vert X_1 + X_2 + \ ldots + X_ {12} = 18) $$ che introduce un termine aggiuntivo basato sulla regola di Bayes.
$$ P (\ forall i: X_i \ leq 4 \ vert \ sum X_i = 18) = P (\ forall i: X_i \ leq 4) \ frac {P ( \ sum X_i = 18 \ vert \ forall i: X_i \ leq 4)} {P (\ sum X_i = 18)} $$
Questo fattore di correzione è il rapporto tra la probabilità che una somma di variabili distribuite di Poisson troncate sia uguale a 18 $ P (\ sum X_i = 18 \ vert \ forall i: X_i \ leq 4 ) $ e la probabilità che una somma di variabili distribuite di Poisson regolari sia uguale a 18, $ P (\ sum X_i = 18) $ . Per una piccola quantità di mesi di nascita e persone nel gruppo questa distribuzione troncata può essere calcolata manualmente
# fattore di correzione di Bruce Levin
correzione <- function (y) {
Nptrunc (y) [19] / dpois (18,18)
}
Nptrunc <- function (lim) {
# distribuzione di Poisson troncata
ptrunc <- dpois (0: lim, 1.5) / sum (dpois (0: lim, 1.5))
## vettore con probabilità
outvec <- rep (0, lim * 12 + 1)
outvec [1] <- 1
#convolve 12 volte per ogni mese
per (i in 1:12) {
newvec <- rep (0, lim * 12 + 1)
for (k in 1: (lim + 1)) {
newvec <- newvec + ptrunc [k] * c (rep (0, k-1), outvec [1: (lim * 12 + 1- (k-1))])
}
outvec <- newvec
}
outvec
}
z2 <- ppois (t, 1.5) ^ 12 * Vettorizza (correzione) (t) # P (max< = t)
z2 [1: 2] <- c (0,0)
dz2 <- diff (z2) # P (max = t + 1)
Risultati
Queste approssimazioni danno i seguenti risultati
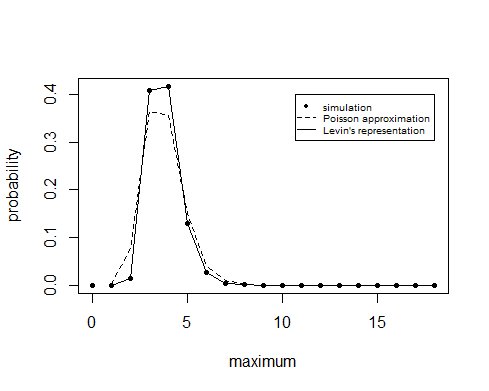
Simulazione > ###
Somma > (y> = 4) / 10 ^ 6
[1] 0,577536
> ### calcolo
> 1-z [4]
[1] 0,5572514
> ### calcolo esatto
> 1-z2 [4]
[1] 0,5771871