Normalmente non chiameresti il valore osservato un "valore stimato".
Tuttavia, nonostante ciò, il valore osservato è nondimeno tecnicamente una stima della media al suo particolare $ x $, e trattarlo come una stima ci dirà effettivamente senso in cui OLS è più bravo a stimare la media lì.
In generale, la regressione viene utilizzata nella situazione in cui se si prendesse un altro campione con gli stessi $ x $, non si otterrebbero gli stessi valori per $ y $. Nella regressione ordinaria, trattiamo $ x_i $ come quantità fisse / note e le risposte, $ Y_i $ come variabili casuali (con valori osservati denotati da $ y_i $).
Usando una notazione più comune, scriviamo
$$ Y_i = \ alpha + \ beta x_i + \ varepsilon_i $$
Il termine rumore, $ \ varepsilon_i $, è importante perché le osservazioni non sono corrette sulla linea della popolazione (se lo facessero non ci sarebbe bisogno di regressione; due punti qualsiasi ti darebbero la linea della popolazione); il modello per $ Y $ deve tenere conto dei valori che assume e, in questo caso, la distribuzione dell'errore casuale tiene conto delle deviazioni dalla linea ("vera").
La stima della media al punto $ x_i $ per la regressione lineare ordinaria ha varianza
$$ \ Big (\ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} \ Big) \, \ sigma ^ 2 $$
mentre la stima basata sul valore osservato ha varianza $ \ sigma ^ 2 $.
È possibile mostrare che per $ n $ almeno 3, $ \, \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} $ non è più di 1 (ma può essere - e in pratica di solito è - molto più piccolo). [Inoltre, quando si stima l'adattamento a $ x_i $ per $ y_i $, rimane anche il problema di come stimare $ \ sigma $.]
Ma invece di perseguire la dimostrazione formale, medita un esempio, che spero possa essere più motivante.
Sia $ v_f = \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum ( x_i- \ bar {x}) ^ 2} $, il fattore per il quale viene moltiplicata la varianza dell'osservazione per ottenere la varianza dell'adattamento a $ x_i $.
Tuttavia, lavoriamo sulla scala dell'errore standard relativo piuttosto che sulla varianza relativa (cioè, guardiamo la radice quadrata di questa quantità); gli intervalli di confidenza per la media in un particolare $ x_i $ saranno un multiplo di $ \ sqrt {v_f} $.
Quindi per l'esempio. Prendiamo i dati di cars in R; si tratta di 50 osservazioni raccolte negli anni '20 sulla velocità delle auto e sulle distanze prese per fermarsi:
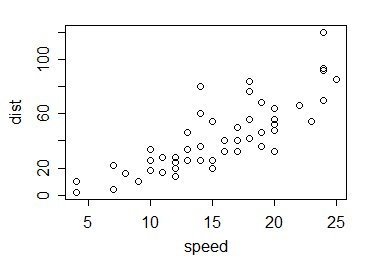
Allora come funzionano i valori di $ \ sqrt {v_f} $ confrontare con 1? In questo modo:
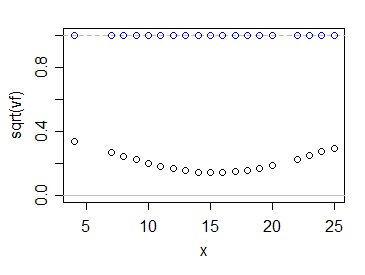
I cerchi blu mostrano i multipli di $ \ sigma $ per la tua stima, mentre quelli neri lo mostrano per la solita stima dei minimi quadrati. Come vedi, l'utilizzo delle informazioni di tutti i dati rende la nostra incertezza su dove si trova la media della popolazione sostanzialmente più piccola, almeno in questo caso, e ovviamente dato che il modello lineare è corretto.
Di conseguenza , se tracciamo (diciamo) un intervallo di confidenza del 95% per la media per ogni valore $ x $ (anche in luoghi diversi da un'osservazione), i limiti dell'intervallo ai vari $ x $ sono tipicamente piccoli rispetto al variazione nei dati:
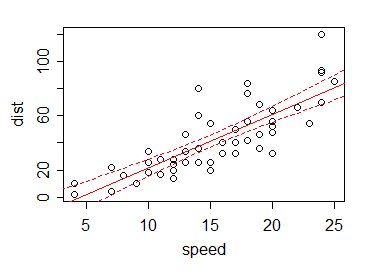
Questo è il vantaggio di "prendere in prestito" informazioni da valori di dati diversi da quello attuale.
In effetti, possiamo utilizzare le informazioni di altri valori - tramite la relazione lineare - per ottenere buone stime del valore in luoghi in cui non abbiamo nemmeno i dati. Considera che nel nostro esempio non ci sono dati a x = 5, 6 o 21. Con lo stimatore suggerito, non abbiamo informazioni lì - ma con la retta di regressione possiamo non solo stimare la media in quei punti (e in 5,5 e 12,8 e così via), possiamo fornire un intervallo, anche se, ancora una volta, uno che si basa sull'idoneità delle ipotesi di linearità (e varianza costante di $ Y $ s e indipendenza).